Carlos Alfredo Torres Cubilla
Data Scientist
Biographie
Carlos Torres ist ein Data Scientist mit fundierten Kenntnissen in Statistik, maschinellem Lernen und Big-Data-Analyse.
Er besitzt sowohl einen Bachelor-Abschluss in Statistik als auch einen Master-Abschluss in fortgeschrittener Analyse multivariater Daten und Big Data von der Universität Salamanca, wo er fundierte Kenntnisse in Programmierung, prädiktiver Modellierung und angewandter Forschung entwickelte.
Carlos verfügt über Erfahrung mit Cloud-Plattformen wie AWS und Databricks, wo er Machine-Learning-Modelle für reale Anwendungen trainiert und implementiert hat. Zuvor war er bei der Banco General tätig , wo er datenbasierte Lösungen zur Optimierung des Krediteinzugs und zur Steigerung der Rentabilität der Bank entwickelte.
Derzeit konzentriert er sich darauf, seine Expertise in fortgeschrittener Analytik und datengestützter Entscheidungsfindung auszubauen, um wirkungsvolle und effiziente Lösungen zu entwickeln, und erforscht gleichzeitig weiterhin neue Anwendungsmöglichkeiten von künstlicher Intelligenz und maschinellem Lernen in realen Kontexten.
Laden Sie meinen Lebenslauf herunter.
- Statistiken
- Künstliche Intelligenz
- Maschinelles Lernen
- Programmierung
Masterstudiengang in fortgeschrittener Analyse multivariater Daten und Big Data,, 2020
Universität von Salamanca
Bachelor-Abschluss in Statistik, 2019, 2019
Universität von Salamanca
Technische Fähigkeiten
Entwicklung von Modellen des maschinellen Lernens, Aufgabenautomatisierung und Datenanalyse
Fortgeschrittene statistische Analyse, Visualisierung und prädiktive Modellierung
Aufbau und Bereitstellung von Daten- und Machine-Learning-Pipelines in kollaborativen Umgebungen
Experimentmanagement und Produktionsbereitstellung von Modellen des maschinellen Lernens
Erfahrung mit S3, EC2 und QuickSight für cloudbasierte Analysen
Versionskontrolle, kollaborative Arbeitsabläufe und reproduzierbare Entwicklung
Grundlegendes Verständnis zum Interpretieren und Bearbeiten von Anfragen
Klare und strukturierte technische Dokumentation in reproduzierbaren Umgebungen
Grundkenntnisse der HTML-Struktur zur Ergebnisdarstellung oder Inhaltsintegration
Fähigkeiten
Fähigkeit, Informationen zu analysieren und datengestützte Entscheidungen zu treffen
Kritischer und kreativer Ansatz zur Bewältigung komplexer Herausforderungen
Flexibilität in dynamischen Umgebungen und Offenheit für neue Technologien
Engagement für lebenslanges Lernen und berufliche Weiterentwicklung
Klarheit und Einfühlungsvermögen bei der Vermittlung technischer und strategischer Ideen
Fähigkeit, Teams zu motivieren, anzuleiten und zu koordinieren, um gemeinsame Ziele zu erreichen
Erfahrung
Apr 2022 – Feb 2025
- Leitete strategische Advanced-Analytics-Projekte im Bankwesen (u. a. Delinquenz Prognosen und Optimierung des Forderungsmanagements) und erzielte dabei erhebliche Verbesserungen bei Portfolio-Rückflüssen.
- Entwickelte und implementierte Machine-Learning-Modelle (Scikit-learn, LightGBM, XGBoost), die mit skalierbaren Pipelines in Databricks in Produktion eingesetzt und über MLflow überwacht wurden.
- Konzipierte robuste ETL-Pipelines in PySpark zur Versorgung von Executive Dashboards in AWS QuickSight und optimierte so die datengetriebene Entscheidungsfindung für das Senior Management.
- Betreute ein Team von Data Scientists und Engineers und förderte Standards im Bereich Data Engineering und Visualisierung im Einklang mit internationalen Best Practices.
Jan 2021 – Mar 2022
- Beteiligung an End-to-End-Analytics-Projekten (u. a. Kreditkarten-Churn, Versicherungsverkäufe, Next Best Product) sowie Integration prädiktiver Modelle in Geschäftsprozesse für Inkasso und Risiko.
- Automatisierte ETL-Prozesse in PySpark und entwickelte prädiktive Modelle in Python, wodurch die Skalierbarkeit und Effizienz analytischer Abläufe erhöhten wurden.
- Erstellte Finanzberichte mit Visualisierungen, die sowohl auf technische als auch nicht-technische Zielgruppen zugeschnitten waren, und erleichterte so die Kommunikation von Ergebnissen.
- Implementierte ETL-Prozesse in R (Tidyverse), um Daten aus verschiedenen Quellen zu konsolidieren und zu bereinigen.
- Entwicklung einer interaktiven Shiny-Anwendung für multivariate Analysen zur verbesserten Datenexploration.
- Erstellung dynamischer HTML-Reports mit interaktiven Visualisierungen zur besseren Kommunikation von Ergebnissen für internationale Kunden.
- Beratete Studierende beim Einsatz fortgeschrittener statistischer Methoden in akademischen Projekten.
- Unterstützung der Lehre in angewandten Statistik-Kursen und Förderung des Einsatzes analytischer Tools.
Projekte
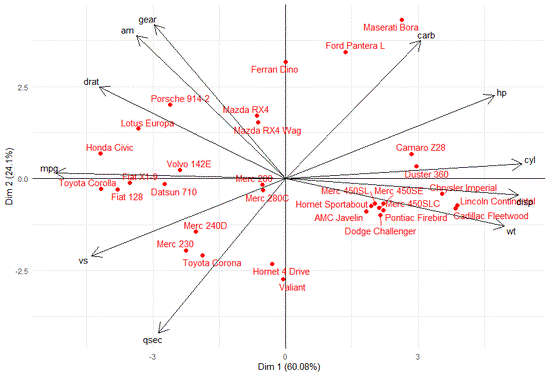
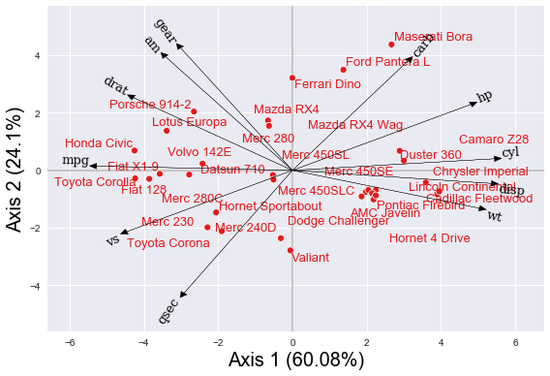
SparseBiplots
R-Paket, das den HJ-Biplot durchführt und Modifikationen zur Einführung von Ridge-, LASSO- und Elastic-Net-Regularisierungen enthält.

Covid-19 in Kastilien und León
Web-App zur Visualisierung des epidemiologischen Status von COVID-19 in Kastilien und León, Spanien.

HackForGood 2019
Das Projekt wurde durchgeführt, um die Herausforderung der künstlichen Intelligenz zur Verbesserung des Gesundheitssystems zu bewältigen.
Veröffentlichungen
Zertifizierungen



Kontakt
- carlos221296@gmail.com
- Wedel, 22880